|

The criteria used to select the representative protein chains are: a) quality of atomic coordinate data, b) sequence uniqueness, and c) conformation uniqueness. The system of PDB-REPRDB is designed so that the user may obtain a quick selection of the representatives according to the priorities specified oneself.
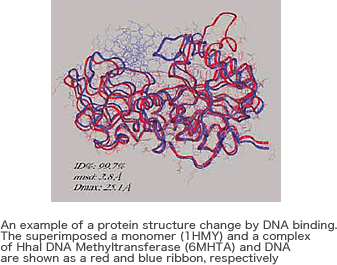
The structural library for protein secondary structure prediction and the data for our PAPIA (Parallel Protein Information Analysis) system were chosen from PDB using the system. And this will be useful for detecting local structure diversity between homologous proteins.
The system is available at the PAPIA WWW server (http://www.cbrc.jp/papia/).

Noguchi,T., Akiyama,Y. : "PDB-REPRDB: a database of representative protein chains from the Protein Data Bank (PDB) in 2003", Nucleic Acids Research , Vol.31, No.1, 492-493 (2003).
Noguchi,T. and Akiyama,Y.: "PDB-REPRDB", Nucreic Acid Research Vol.31, No. 1 Online summary paper, http://www3.oup.co.uk/nar/database/summary/277 (2003).
Onizuka, K., Noguchi, T., Akiyama, Y., and Matsuda, H. : "Using Data Compression for Multidimensional Distribution Analysis", IEEE Intelligent Systems, 17, 3, pp.48-54 (2002).
Noguchi, T., Matsuda, H., Akiyama, Y. :"PDB-REPRDB: a database of representative protein chains from the Protein Data Bank (PDB)", Nucleic Acids Research, 29, 1, pp.219-220 (2001).
Noguchi, T., Ito, M., Matsuda, H., Akiyama, Y., Nishikawa, K. :"Prediction of Protein Secondary Structure Using the Threading Algorithm and Local Sequence Similarity", Research Communications in Biochemistry, Cell & Molecular Biology, 5, 1&2, pp.115-131 (2001).
|