
- チーム
- アルゴリズムチーム
- ゲノム配列情報チーム
- 生体分子情報チーム
- ネットワーク情報チーム
- プロジェクト
- 人材養成
アルゴリズムチーム
本チームでは、個人ゲノム解析に必要な高速アルゴリズムの開発を行う。特に、次世代シークエンスデータ解析手法の開発、異種多様データからの組合せ要因の推定技術、および、プライバシ保護データマイニングに重点を置く。
組合せ要因の多重検定法
自然科学で得られるデータ量は増加の一途をたどり、これらを有効に解析できる方法が望まれている。しかし、従来の統計検定手法では観測できる対象が増えれば増えるほど、統計的有意性(発見)の基準を厳しくしなくてはならない。特に、複合的な組み合せ因子に対して極めて保守的な検定値 (p値)を出すことが多く、有意義な実験結果が不当に低く評価されることがあった。本チームでは、超高速アルゴリズムの技法を用いて、従来法より、格段に精度の高いp値を算出する新手法LAMP(Limitless Arity Multiple-testing Procedure)を開発した(図)。転写因子の組み合わせ効果の研究をはじめ、複数の遺伝子が原因となっている疾病や多数の部位が関わる脳の高次機能の解明など複合要因に起因する現象の解明が加速されることが期待される。
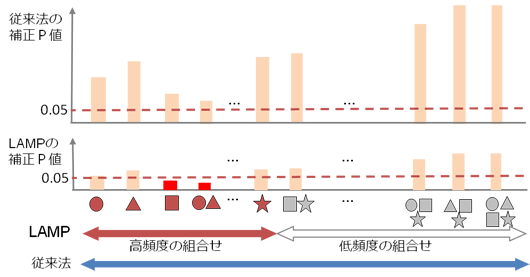
図:LAMPによる多重検定
プライバシ保護マイニング
本チームでは、セキュアシステム研究部門と共同で、生命科学データに関するプライバシ保護データマイニング技術の研究を行っている。このプロジェクトにおいては、ゲノムデータを扱う際に個人情報が漏洩することを防ぐため、準同型暗号等の高機能暗号を用いて、暗号化したデータを一度も復号しないまま処理する秘匿検索技術を開発している。これまで化学物質データベースの秘匿検索技術や、楕円曲線暗号に基づく秘匿計算ライブラリの開発などを行ってきたが、今後は、ゲノム診断など、個人ゲノム関連の分野にも注力する予定である。
Team Member




page top