
- チーム
- アルゴリズムチーム
- ゲノム配列情報チーム
- 生体分子情報チーム
- ネットワーク情報チーム
- プロジェクト
- 人材養成
ゲノム配列情報チーム
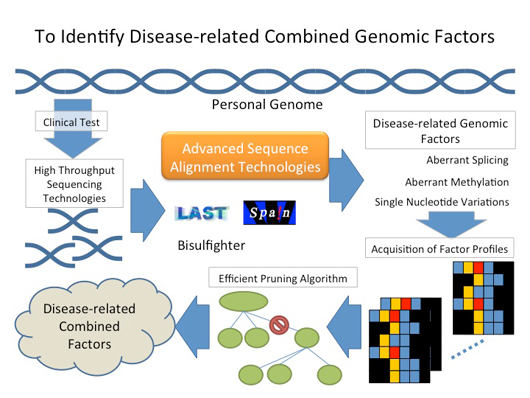
一卵性・二卵性双生児の比較調査などから、多くの疾病において遺伝的要因が重要な役割を担っており、ゲノムの個人差が罹患率や罹患して治療を受けた場合の予後を大きく作用することが明らかになっている。また、エピゲノム状態に影響される遺伝子発現の異常も、がんなどの予後予測や最適な薬剤投与の重要な指標になる。これらの異常のうち、現在の次世代DNAシークエンスデータの情報解析により正確に検出できるものは、個人の点変異遺伝子多型(SNV)など、比較的検出しやすい種類の異常に限られている。一方、トランスポゾンやウイルスゲノムの挿入、繰り返し配列の長短異常、低レベルに発現されるスプライシング異常、検体の中の一部の細胞だけ(がん幹細胞など)に見られる突然変異なども疾病に関与することが知られているが、現状の技術では正確な検出が難しい。
ゲノム配列情報チームは、本研究センターの類似配列検索技術をベースに、確率モデルの拡張と計算アルゴリズムに工夫を加えることにより、これらの重要な問題の解決を目指す。具体的には、まず検体細胞中頻度の少ない突然変異と融合遺伝子などの染色体再編、ゲノム挿入、低発現のスプライシング異常、DNAメチル化異常、各種ゲノム異常を検出するシステムを開発し、シークエンシング・カバー率100x以上の条件で検体全体の5%を超える差異の検出を目標とする。また、多くの疾病は、突然変異と遺伝子多型、遺伝子発現異常、DNAメチル化異常など様々な疾病関連因子が組み合わさって関与することが知られている。しかし、ありうる組合せ数が膨大であるため、疾病関連因子を同定することは計算量的に困難である。これらの問題を解決するために、ゲノムスケールの新規多重検定を利用した統計的な手法と、ゲノム異常の影響を立体構造や細胞内局在のレベルで予測する技術を組み合わせた疾病関連因子組合せ推定法を開発する。
最終的には、これらの技術を実際のゲノム医療の現場からの要望に応えるかたちで提供することが目標である。これは容易な目標ではないが、幸いにしてゲノム情報研究センターには、配列解析分野で非常に有力な研究者が集っている。このような千載一遇の機会をとらえつつ、外部研究機関との連携を密にして、これらの課題に挑戦していきたい。
Team Member


Martin Frith マーティン・フリス

キーワード
genome evolution, motifs, genome function, alignment, repeats


Thomas Poulsen トーマス ポールセン
特別研究員

キーワード
Sequence alignment, Series quantification, Localization prediction.
page top