Computational Biology Research Center[CBRC]
Advanced Industrial Science and Technology[AIST]| Key Word Search |

|
- Genome
Informatics - RNA Informatics
- Sequence Analysis
- Comparative Genomics
- Molecular Informatics
- Biomolecule Analysis
- Cellar
Informatics - Cellular Systems Analysis
- Integration of Biological Information
- Integration of Biological Information
- Machine Learning
- Project
- Fostering Human Resources
- Top
- >
- Organization
- >
- RNA Informatics Team
RNA Informatics Team

Research Topics
The aim of RNA Informatics Team is to build a data analysis infrastructure for transcriptome and epigenome.
Modern bio-industry has long been seeing the age of mass data analysis. Thusly, we have to meet the requirement of the industry to develop data analysis infrastructure for efficient knowledge discovery from the mass data. Such the infrastructure includes a sequence mapping tool, a RNA secondary structure prediction tool, a database that integrates raw data and their derived results, a genome browser and a bioinformatics workbench that help searching, browsing, and reusing data from a database. In order to realize the aim, we are currently committing the following research themes: Development of RNA data analysis tools[1, 2, 3], Development of fast sequence data analysis tools[4], Development of the Functional RNA database [5], and Development of an epigenome database.
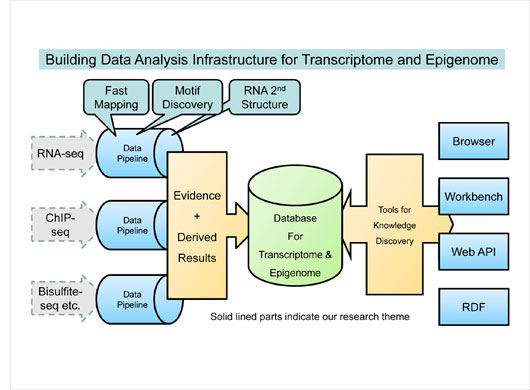
■click for full size(31KB)
Team Member
Toutai Mituyama


Key Words
database, microarray, noncoding, microRNA, giga sequencer
Kazutaka Katoh
Research Scientist

Key Words
Sequence alignment, Molecular evolution, Molecular phylogenetic analysis
Kana Shimizu

Key Words
sequence analysis, algorithm, giga-sequencer, protein intrinsic disorder
Yutaka Saito
Research Staff

Key Words
Epigenetics, Functional RNA, Noncoding RNA, Sequence analysis, Kernel methods
Papers List
- ■ Hamada, M., Yamada, K., Sato, K., Frith, M., Asai, K., "CentroidHomfold-LAST: accurate prediction of RNA secondary structure using automatically collected homologous sequences", Nucleic Acids Res. Vol. 39 Web Server issue, W100-W106, (2011).
- ■ Terai, G., Mituyama, T., Asai, K., "Prediction of conserved miRNA precursors and their mature forms by integrating positionspecific structural features, Aural presentation", The 16th Annual Meeting of The RNA Society and The RNA Society of Japan 13th, (2011).
- ■ "Searching for Structural RNA Motifs by Using the Energy Model of Secondary Structures", Aural presentation, The 16th Annual Meeting of The RNA Society and The RNA Society of Japan 13th, (2011).
- ■ Shimizu, K., "Fast and exact algorithm for Next Generation Sequencing data analysis", Aural presentation, ISMB/ECCB, (2011).
- ■ Mituyama, T., "An identification of secondary structure conserved elements in mammalian syntenic regions", Aural presentation, IEEE International Conference on Systems Biology, (2011).